 |
Strangeness Reconstruction - Cuts Optimization |
What's new:
The whole page is new!!!(12/05/99)
.gif)
I - Introduction:
The V0 reconstruction corresponds to the identification of the decay of a neutral particle
to two opposite charged ones. The neutral particle does not produce a track in the experimental apparatus,
while their daughter particles do.
Therefore, the V0 reconstruction is performed searching for pair of tracks with opposite charge
that satisfy certain geometrical criteria, i.e, that form a V shape topology, as illustrated in figure I.1.
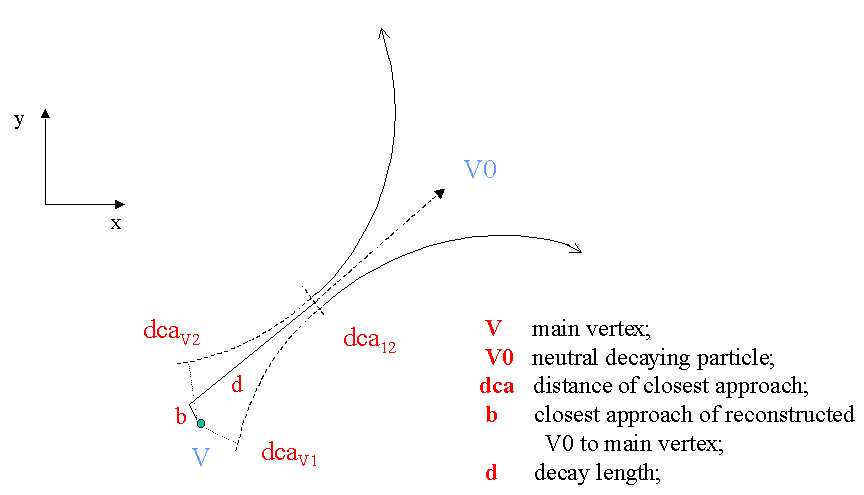 Figure I.1: Schematic representation of a V0.
The geometrical cuts used to identify it are: decay distance (d), impact parameter (b),
distance of closest aproach of daughter tracks to primary vertex (dcaV1 and dcaV2) and
distance of closest aproach between daughter tracks (dca12)
Figure I.1: Schematic representation of a V0.
The geometrical cuts used to identify it are: decay distance (d), impact parameter (b),
distance of closest aproach of daughter tracks to primary vertex (dcaV1 and dcaV2) and
distance of closest aproach between daughter tracks (dca12)
The goal of this study is to evaluate and try to improve the current cuts applied to the V0 reconstruction.
Two quantities are used to evaluate the performance of the V0 reconstruction:
 yield exclusive of the V0 reconstruction, i.e., it corresponds to the number of true V0s reconstructed
divided by the number of true V0s that have both daughter tracks reconstructed by the TPC software.
This way we exclude the effect of tracking reconstruction and focus on V0 reconstruction;
yield exclusive of the V0 reconstruction, i.e., it corresponds to the number of true V0s reconstructed
divided by the number of true V0s that have both daughter tracks reconstructed by the TPC software.
This way we exclude the effect of tracking reconstruction and focus on V0 reconstruction;
purity, that corresponds to the number of true V0s obtained divided by the total number of
reconstructed V0s.
II - Current Status:
Currently, the V0 reconstruction code applies the set of default geometrical cuts listed bellow:
decay distance (d) > 2.0 cm
impact parameter (b) < 0.7 cm
distance of closest aproach of daughter tracks to primary vertex (dcaV1 and dcaV2) > 0.8 cm
distance of closest aproach between daughter tracks (dca12) < 0.7 cm
and, the kinematical cuts (Armenteros plot):
 alpha Armenteros < 1.2
alpha Armenteros < 1.2
pt Armenteros < 0.3 GeV/c
Naturally, these cuts are not optimized and the ratio signal to background(purity) is very low.
One attempt to get optimized cuts was performed by Matt Lamont,
and he got to the following values for these cuts:
decay distance (d) > 5.0 cm
impact parameter (b) < 0.3 cm
distance of closest aproach of daughter tracks to primary vertex (dcaV1 and dcaV2) > 2.0 cm
distance of closest aproach between daughter tracks (dca12) < 0.8 cm
number of TPC hits on tracks > 10 (extra cut)
and, the kinematical cuts (Armenteros plot):
0.5 < alpha Armenteros < 1.0 (Lambdas)
0.10 < pt Armenteros < 0.25 GeV/c (K0)
Table II.1 shows some numbers obtained from 50 HIJING events (produced on July,99).
| CUTS | #TRUE V0(K0)/event |
#FALSE V0 (K0 mass +/- 10MeV/c2)/event |
Purity (%) | Yield (%) |
|---|
| Default | 7.6 | 13.9 | 35.3 | 23.3 |
| Matt's | 1.1 | 0 | 100 | 3.4 |
Table II.1:
Quantities obtained from 50 Hijing events (file produced on July,99).
From this table, one notices that the default cuts are not optimized for purity, i.e.,
the background level is too high. Matt's number are very well tunned for purity purposes.
However, the yield level is very low.
Figure II.1 shows the distribution of the geometrical parameters (and the Armenteros plot as well)
for true (K0, black histogram) and false V0s (red histogram).
I try to normalize both distributions, so the yield of the distributions are mean less.
The important feature is the shape of each distribution.
The dashed-dotted blue line shows the default cuts
(sharp cutoff in the histograms), while the dotted purple(?) line shows where Matt's cuts are located.
We see that the parameter distribution of false V0s has a much faster drop
(or raise, in the case of impact parameter) than the distribution of parameters for true V0s.
Matt's cuts are very well placed, selecting the region of the space after (or before)
the rapid drop (raise) of the parameter distribution of false V0s.
*** K0 ***
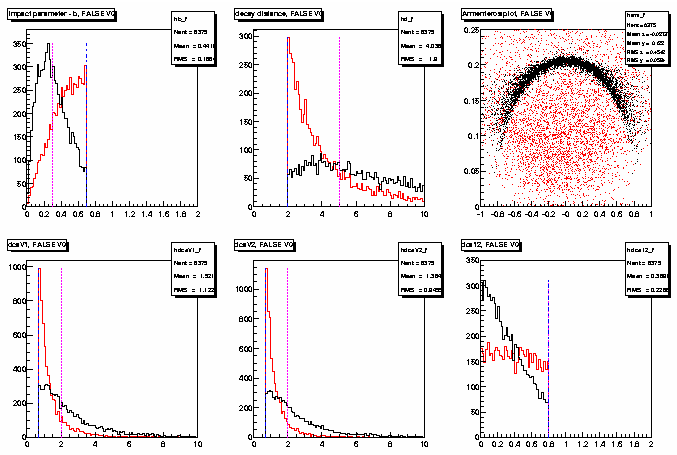 Figure II.1:distribution of the geometrical parameters
(and the Armenteros plot as well) for true (K0, black histogram)
and false V0s (red histogram) for (from left to right, top to bottom):
b, d, Armenteros plot, dcaV1, dcaV2, dca12.
The dashed-dotted blue line shows the default cuts (sharp cutoff in the histograms),
while the dotted purple(?) line shows where Matt's cuts are located.
Figure II.1:distribution of the geometrical parameters
(and the Armenteros plot as well) for true (K0, black histogram)
and false V0s (red histogram) for (from left to right, top to bottom):
b, d, Armenteros plot, dcaV1, dcaV2, dca12.
The dashed-dotted blue line shows the default cuts (sharp cutoff in the histograms),
while the dotted purple(?) line shows where Matt's cuts are located.
Another attempt to study the cut space was made relaxing (instead of tighting up) the cuts during the
reconstruction of the vertices. Obviously, a mechanism was created to reject most of the false V0s,
otherwise we would be swamped by them. And this is possible only with simulated data...
Following is a list of the relaxed cuts used:
decay distance (d) > 0.5 cm
impact parameter (b) < 2.0 cm
distance of closest aproach of daughter tracks to primary vertex (dcaV1 and dcaV2) > 2.0 cm
distance of closest aproach between daughter tracks (dca12) < 0.01 cm
and, the same kinematical cuts were used.
Figure II.2 shows the distribution of the geometrical parameters (and the Armenteros plot as well)
for true (K0, black histogram) and false V0s (red histogram) obtained with these new cuts.
*** K0 ***
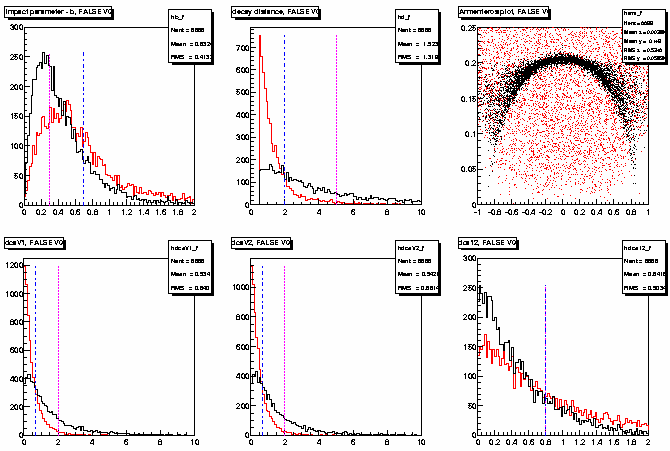 Figure II.2:distribution of the geometrical parameters
(and the Armenteros plot as well) for true (K0, black histogram)
and false V0s (red histogram) for (from left to right, top to bottom):
b, d, Armenteros plot, dcaV1, dcaV2, dca12.
The dashed-dotted blue line shows the default cuts (sharp cutoff in the histograms),
while the dotted purple(?) line shows where Matt's cuts are located.
In this case, more relaxed cuts were applied during reconstruction (see text).
Figure II.2:distribution of the geometrical parameters
(and the Armenteros plot as well) for true (K0, black histogram)
and false V0s (red histogram) for (from left to right, top to bottom):
b, d, Armenteros plot, dcaV1, dcaV2, dca12.
The dashed-dotted blue line shows the default cuts (sharp cutoff in the histograms),
while the dotted purple(?) line shows where Matt's cuts are located.
In this case, more relaxed cuts were applied during reconstruction (see text).
Next, the efficiency for the default cuts (square dots or higher values) and Matt's cuts
(circle dots or lower values) was calculated as a function of pt.
The result can be seen on figure II.2. This plot just reflects the value of yield obtained by both cuts.
*** K0 ***
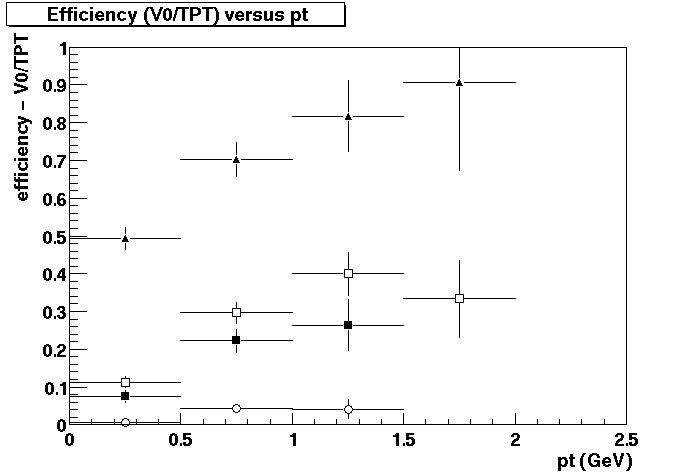 Figure II.3:efficiency for the default cuts (square dots or higher values) and
Matt's cuts (circle dots or lower values)
Figure II.3:efficiency for the default cuts (square dots or higher values) and
Matt's cuts (circle dots or lower values)
Naturally, these are not final numbers (just the current status as I see it) and only the real data can
provide a final answer. However, one can try to improve the analysis studying the cut phase space and
using different techniques to apply the geometrical cuts besides tha traditional straight cut approach.
III - Neural Network:
What is a Neural Network?
The idea
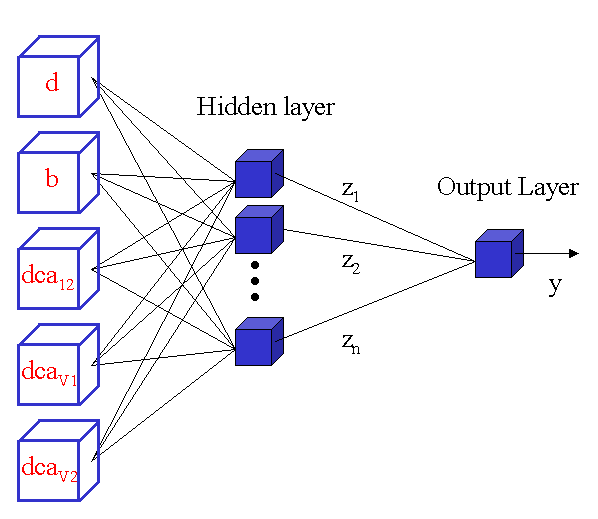 Figure III.1:
Figure III.1:
Why use a Neural Network for V0 reconstruction?
The various geometrical parameters used to
This technique has already been used with success in other experiments for V0 reconstruction
(see for example nucl-ex/9612001).
IV - Procedure:
There are basically two steps for the neural net approach: the training of the net and its evaluation.
I started the training using a "home made" routine written by Bonglea Kim, from Wayne State University.
Since the results were not very encouraging, I decided to start using a very well known (professional) software,
created by the Applied Computer Science Department from the University of Stuttgart.
The package is called SNNS (Stuttgart Neural Network Simulator) and it's available at the
University of Stuttgart web page.
There are MANY parameters that one can choose in order to train the net. Some of these are:
-
number of units in the input layer;
- restricted to the number of parameters available. In this case, 5 (listed in figure III.1).
-
number of hidden layers;
-
number of units in each hidden layer;
- So far, I've tested two configurations:
- (i)
1 hidden layer with 10 neurons;
- (ii)
2 hidden layers: the first one with 5 neurons and the second one with 3 neurons;
-
learning algorithm;
- I tried just one:
-
standard backpropagation;
-
parameters of the learning function;
- There are two parameters for the standard backpropagation algorithm:
-
learning rate (a number between 0 and 1);
-
maximum error that is tolerated;
-
number of cycles;
-
training set;
- I believe this is the most influential item of the training process.
The sample of parameters chosen must reproduce in the best way possible
the behavior of the entire universe of parameters.
- I've used three samples of parameters to train the net:
- (i)
The parameters of 6323 TRUE V0s (K0) and 11993 FALSE V0s
taken from ~1000 Hijing events (created on ???),
where the default cuts were applied previously to the selection of the parameters
(these Hijing files correspond to regular production files).
- (ii)
The parameters of 7174 TRUE V0s (K0s) and 20061 FALSE V0s
taken from ~400 Hijing events (created for MDC3),
where the default cuts were applied previously to the selection of the parameters.
- (iii)
The parameters of ??? TRUE V0s (K0s) and ??? FALSE V0s
taken from ~250 Hijing events (created on Feb., 2000),
where relaxed cuts were applied previously to the selection of the parameters
(d > 0.5 cm, b < 2.0 cm, dcaV1 > 2.0 cm,
dcaV2 > 2.0 cm, dca12 < 0.01 cm).
V - Partial Results:
Just to have a feeling of the dependence of the neural network results with different parameters,
various tests were performed. Table V.1 lists some of these tests and table V.2 shows the results
of these tests for 50 Hijing events. Naturally, these events were not used to train the net.
| Network Label | Network Configuration |
Learning Rate | Number of Cycles | Training Set |
|---|
| NET1(net14) | (i) | 0.2 | 20,000 | (i) |
| NET2(net23) | (i) | 0.02 | 10,000 | (i) |
| NET3(net83) | (i) | 0.002 | 10,000 | (i) |
| NET4(net103) | (i) | 0.0002 | 10,000 | (i) |
| NET5(net107) | (i) | 0.0002 | 200,000 | (i) |
| NET6(net205_2) | (i) | 0.002 | 50,000 | (iii) |
| NET7(net215) | (i) | 0.0002 | 50,000 | (iii) |
| NET8(net2L32) | (ii) | 0.0002 | 100,000 | (iii) |
Table V.1: List of tests performed up to this moment.
| Network Label | #TRUE V0 (K0)/event |
#FALSE V0 (K0 mass +/- 10MeV/c2)/event |
Purity (%) | Yield (%) |
|---|
| NET1 | | | | |
| NET2 | | | | |
| NET3 | | | | |
| NET4 | | | | |
| NET5 | | | | |
| NET6 | | | | |
| NET7 | | | | |
| NET8 | | | | |
Table V.2: Quantities obtained from 50 Hijing events (same as table II.1)
for the various networks tested.
VI - Conclusion:
Please send comments and suggestions to Marcelo Munhoz:
munhoz@physics.wayne.edu
(Last
update: February 7, 2000)