From the previous talk, Preshower, it seems that the peak could be sitting on a non uniform background
To investigate this further I have tried several different background mixing methods, first I shall go over how these were developed and then I will give a review of the current state of this investigation
All methods must form a "mimic" pair with one track passing the L0 trigger cut and the other track passing the L2 trigger cut (see last weeks talk).
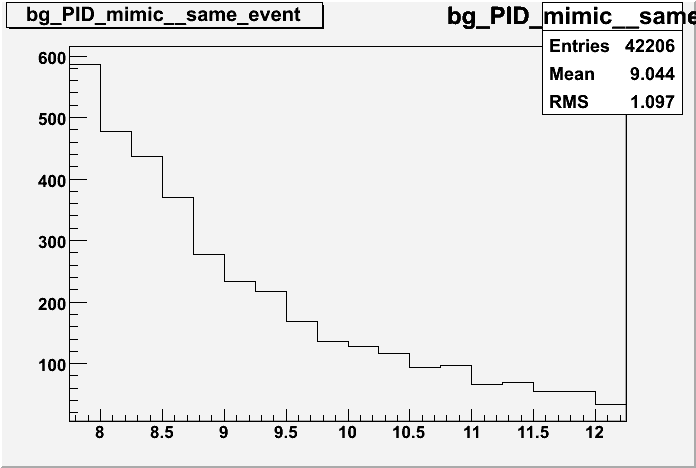
Currently we pair + with + and - with - in the event we wish to find Upsion signal (+ with -) in the same event
Easy to code, easy to normalise
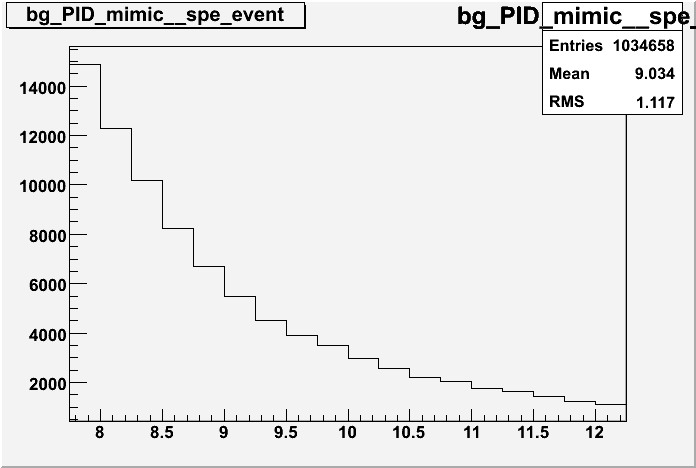
Mixing across different events preseves any correlations
Limited and fixed statistics prone to fluctuations
Could be physical correlations between ++ and -- tracks in the event that will deviate from a pure background assumption
This was the simpelest solution and the point where I started to develope the code:
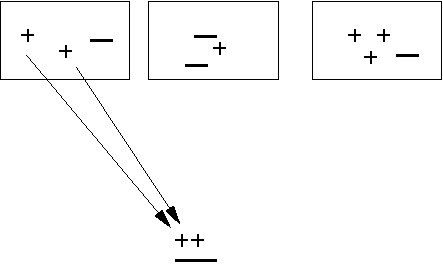
The boxes represent events, each containing + and - tracks
The box on the left hand side is our current event, + and - tracks here are paired with + and - tracks from other events
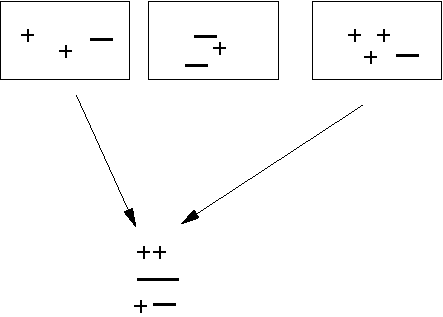
The arrows show where the tracks from one event are paired with the tracks from another
Unlimited background statistics, just pick as many as you want
Events are true background, tracks can't be correlated over events (depending on shape this could also be a "con")
Increased statistics for +- tracks
No vertex or multiplicity correlation between events
Events picked at random ramp up computing time to collosal level
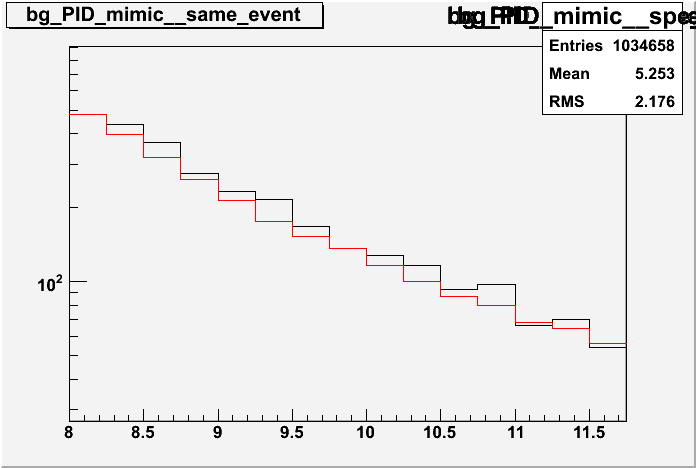
The multiplicity and vertex problem was fixed by adding a dynamic array, a first pass though the data uses these arrays to bins the vertex and multiplicity of each event. Then when the code starts paring tracks between events, it use these bins as a reference to mix events with a similare multiplicity and vertex
Only the first primary vertex in events were mixed with the first primary vertex from different events as this dramatically simplifed the code
The computing time problem came from the large input file size, the TTree is much larger then the memory and only seems to store part of the tree in memory at one time If you pick wildly different events the postions in the TTree are likley still on disk and not in memory. This slows the computing time down by up to orders of 1000. This was fixed by tagging the multiplicity array and vertex array with the location in the TTree of these events, then picking points in the bin that were close to the current event in memory
Pros: all the above
Cons: probably a pain to normalise, currently using the ratio of the background integral to the signal integral but a track by track normalisation would be better (next iteration will remove the peak region, i.e. normailise from 6-8 GeV and 11-15 GeV)